Общее определение понятия семантика это изучение значений. (Слово семантика происходит от греческого понятия semantikos, т.е. "важное значение", а в основе последнего лежит слово sema, т.е. знак). Семантические технологии Web помогают выделять полезную информацию из данных, содержания документов или кодов приложений, опираясь на открытые стандарты. Если компьютер понимает семантику документа, то это не означает, что он просто интерпретирует набор символов, содержащихся в документе. Это значит, что компьютер понимает смысл документа. Семантические технологии Web очерчивают общие рамки, позволяющие осуществлять обмен данными и их многократное использование в различных приложениях, корпорациях и даже сообществах. Семантические технологии Web это эффективный способ представления данных в интернете. Такую структуру также можно символически отождествить с базой данных, которая связана в глобальном масштабе с содержанием документов в интернете. Причем эта связь осуществляется способом, понятным компьютерам. Семантические технологии представляют значения с помощью онтологии и обеспечивают аргументацию, используя связи, правила, логику и условия, оговоренные в онтологии.
К семантическим технологиям Web относятся следующие:
- Глобальная схема имен (URI);
- Стандартный синтаксис описания данных (RDF);
- Стандартные способы описания свойств данных (схема RDF);
- Стандартные способы описания связей между объектами данных (онтология, определяемая с помощью онтологического языка Web (Web Ontology Language)).
Глобальная схема имен URI
URI это просто идентификатор Web, т.е. адреса, начинающиеся с http или ftp. Любой пользователь может создать URI, но права собственности на них четко организованы, поэтому они представляют идеальную базовую технологию для построения глобальной сети. Фактически, интернет является именно такой структурой: все, что имеет URI, считается находящимся в глобальной сети. Любой объект, схема или модель данных семантической сети должны иметь собственный уникальный адрес (URI).
Универсальный указатель ресурсов (Uniform Resource Locator, сокр. URL) это URI, который, помимо идентификации ресурса, указывает на способ действия или представления ресурса путем описания основного механизма доступа к нему или его положения в сети. Например, URL http:// www. webifysolutions.com это URI, который идентифицирует ресурс (домашняя страница компании Webify Solutions) и указывает, что его представление (т.е. текущий код HTML домашней страницы как набор закодированных символов) можно получить по протоколу HTTP с сетевого www. webifysolutions. com.
Универсальное имя ресурса (Uniform Resource Name, сокр. URN) это URI, который идентифицирует ресурс с помощью имени в определенном пространстве имен. Оно позволяет говорить о ресурсе без использования его местоположения или снятия ссылок на него. Например, URN urn: ISBN:1-0-7666-98-0 это URI, который, аналогично номеру ISBN, позволяет упоминать книгу, но при этом не указывает, где и как ее можно приобрести.
Стандартный синтаксис описания данных RDF
RDF это спецификация, которая определяет модель представления мира и синтаксис для сериализации и обмена этой модели. Консорциум всемирной сети (World Wide Web Consortium, сокр. W3C) разработал XML-сериализацию для RDF. RDF XML это стандартный формат обмена для RDF в семантической сети, хотя он не является единственным. Например, Notation 3 это отличная тестовая альтернативная сериализация.
RDF обеспечивает последовательный стандартный способ описания и работы практически с любыми интернет ресурсами: от текстовых страниц и графиков до аудиофайлов и видеоклипов. Он предлагает синтаксические возможности для взаимодействия сетей и формирует базовый слой для создания семантической сети. RDF определяет управляемые графы связей, представленные тройками объект-атрибутзначение. Например, объект О имеет атрибут А со значением V.
В листинге 1 представлен пример RDF XML.
Листинг 1. Пример RDF XML
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22rdf-syntax-ns#" xmlns:contact="http://www.w3.org/2000/05/c ontact#">
<contact: Company rdf:about="http:// www. w3. org/ Organization/ contact# Webify Solutions">
<contact:name>Webify Solutions</contact:name>
<contact:mailbox rdf:resource="mailto:info@webifysolutions.c om"/>
<contact:phone>1-8004WEBIFY</contact:phone>
</contact:Company>
</rdf:RDF>
Элемент RDF в листинге 1 несет информацию о ресурсе, в данном случае это компания http: // www. w3. org/ Organization/ contact # We bify Solutions.
Компания может быть идентифицирована по URI http:// www. w3. org/ Organization/contact#WebifySolutions;
ее название Webify Solutions, ее email info@webifysolutions.com, а номер телефона 1-800-4WEBIFY.
На Рис. 1 показан управляемый граф связей, представляющий ту же информацию.
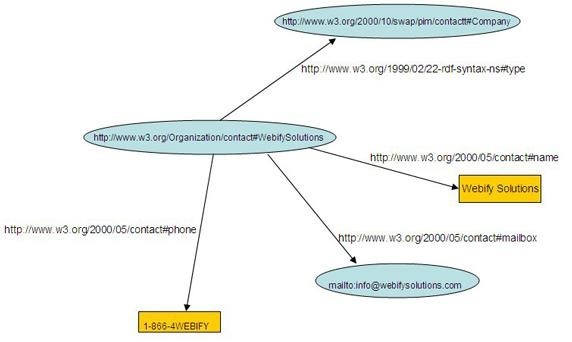
Рис. 1. Граф RDF, описывающий контактную информацию компании Webify Solutions
Схема RDF это семантическое расширение RDF. Она обеспечивает механизмы описания связанных ресурсов, а также, собственно, этих связей.
Система классов и свойств схемы RDF похожа на систему типов языков объектно-ориентированного программирования, таких, например, как Java, но отличается от многих других систем. Так, описательный язык словаря RDF определяет свойства в терминах того класса ресурсов, к которому эти свойства относятся. Другие системы же описывают класс в терминах свойств его элементов.
RDF и схема RDF основаны на XML и схеме XML. Существование стандартов для описания данных (RDF) и их атрибутов (схема RDF) позволяет создавать пакеты легко доступных инструментов для чтения и использования данных из многочисленных источников. То, насколько глубоко различные приложения могут обмениваться данными и использовать их, иногда называется синтаксическим взаимодействием сетей (syntactic interoperability). Чем более стандартизированными и распространенными являются эти инструменты работы с данными, тем выше степень синтаксического взаимодействия сетей, и тем легче и привлекательнее становится использование подхода на основе семантических сетей по сравнению с точечными интеграционными решениями.
Синтаксическое взаимодействие сетей необходимое условие для того, чтобы множественные приложения могли по настоящему "понимать" данные и работать с ними как с информацией. Это также необходимое условие для корректной проверки данных. Синтаксическое взаимодействие сетей требует преобразования ("отображения") между терминами, для чего, в свою очередь, необходим контент-анализ.
Такой контент-анализ требует формальных и подробных спецификаций моделей доменов, которые определяют используемые термины и их связи. Подобные формальные модели доменов иногда называются онтологиями. Они определяют модели данных в терминах классов, подклассов и свойств.
Онтологический язык Web (Web Ontology Language), рекомендуемый консорциумом W3C, помогает в выражении онтологий. Рабочий онтологический язык (Ontology Working Language, сокр. OWL) добавляет больше словарных возможностей для описания свойств и классов, чем RDF или схема RDF. В частности, он позволяет описывать связи между классами (например, неперекрываемость), мощность множества (например, "ровно один"), равенство, более богатую типологию свойств и их характеристики (например, симметрия).
Онтологический язык Web на основе OWL разработан для использования приложениями, которые должны работать с содержанием информации, а не просто предоставлять ее пользователю. OWL улучшает возможности автоматической интерпретации содержимого интернета по сравнению с теми, что могут обеспечить XML, RDF и схема RDF. Это происходит благодаря тому, что OWL предоставляет дополнительные словарные возможности, наряду с формальной семантикой. OWL включает три подъязыка: полный OWL (OWL Full), OWL DL и облегченный OWL (OWL Lite) (перечислены в порядке убывания их выразительных возможностей).
- Полная версия онтологического языка Web на основе OWL называется OWL Full. Этот язык использует все базисные элементы языка OWL и позволяет комбинировать их случайным образом с RDF и схемой RDF. Полный OWL совместим "снизу вверх" с RDF, как синтаксически, так и семантически: любой разрешенный документ RDF является также разрешенным документом OWL Full. Маловероятно, что какие-либо интеллектуальные программные средства способны поддерживать все возможности OWL Full, поскольку этот язык предлагает максимум выразительных средств и синтаксической свободы RDF при отсутствии вычислительных гарантий.
- OWL DL предназначен для тех пользователей, кому необходим максимум выразительных средств без потери вычислительных возможностей. OWL DL это подъязык конструкций языка OWL Full с некоторыми ограничениями, такими как разделение типов (type separation) (например, класс не может быть одновременно индивидуальным элементом или свойством, а свойство не может одновременно быть индивидуальным элементом или классом).
- OWL Lite предназначен для пользователей, которым необходима классификационная иерархия и простые ограничительные возможности. Преимуществом этого языка являются большая легкость его понимания и внедрения по сравнению с двумя другими. Но в то же время его выразительные возможности гораздо ниже. Например, хотя OWL Lite и поддерживает ограничения мощности множества, единственными допустимыми значениями этого параметра являются 0 или 1.
Примерами онтологий являются каталоги сайтов интерактивных покупок, таких, как Amazon.com, стандартные терминологии той или иной области деятельности, например, UNSPSC The United Nations Standard Products and Services Code (система стандартных продуктов и услуг ООН), или различные таксономические системы интернета, такие, как категории сайта "My Yahoo".
Основные компоненты OWL включают классы, свойства и индивидуальные элементы.
Классы это основные блоки онтологии OWL. Класс это концепция в домене. Классы обычно образуют таксономическую иерархию (т.е. систему подкласс-надкласс). Классы определяются с помощью элемента owl:Class. В языке OWL существует два заранее определенных класса: owl: Thing и owl: Nothing. Первый из них является наиболее общим и включает все, второй это пустой класс. Любой класс, определяемый пользователем, является подклассом класса owl: Thing и надклассом класса owl: Nothing. Примеры классов в области банковского дела могут включать классы Account или Customer.
В листинге 2 представлен пример класса OWL.
Листинг 2. Пример класса OWL
<owl:Class rdf:ID="SavingsAccount">
<rdfs:subclassOf rdf:resource="#Account"/>
</owl:Class>
Код в листинге 2 указывает, что элемент Saving Account это класс, являющийся подклассом класса Account.
OWL поддерживает шесть основных способов описания классов. Самый простой это класс с именем (named). Другие типы это классы пересечений (intersection), объединений (union), дополнений (complement), ограничений (restrictions) и классы перечислений (enumerated). В листинге 2 представлены два из этих способов описания классов: класс ограничений определяет Saving Account как подкласс класса с именем Account.
Свойства включают две основные категории:
- свойства объекта (Object properties), которые связывают индивидуальные элементы между собой;
- свойства типов данных (Data type properties), которые связывают индивидуальные элементы со значениями типов данных, такими как целые числа, числа с плавающей запятой и строки. Для определения типов данных OWL использует схему XML.
Свойство может включать домен и некоторую область, связанную с ним. Любое свойство попадает в одну из следующих категорий:
- функциональная: для любого объекта свойство может принимать только одно значение (например, возраст, рост или вес человека);
- обратно-функциональная: два различных индивидуальных элемента не могут иметь одно и то же значение. Например, у каждого человека свой уникальный номер банковского счета bank Number или так называемый SSN (social security number);
- симметричная: если свойство связывает элемент А с элементом В, то из этого можно сделать вывод, что оно также связывает элемент В с элементом А. Примеры симметричных свойств включают выражения типа "является братом (сестрой)" или "такой же, как";
- транзитивная: если свойство связывает элемент А с элементом В, а элемент В с элементом С, то можно предположить, что оно также связывает элемент А с элементом С. Например, если А выше В, а В выше С, то А выше С.
К классам и свойствам могут применяться различные ограничения. Например, ограничения мощности множества указывают на число связей, в которых может участвовать класс или индивидуальный элемент.
Индивидуальные элементы это элементы классов; свойства могут связывать их друг с другом. Например, индивидуальный элемент Smith может быть описан как элемент, принадлежащий классу Person (индивидуум). Свойство has Employer (имеет работодателя) может связывать его с другим индивидуальным элементом Webify Solutions, указывая, таким образом, что Smith работает в компании Webify Solutions.
В листинге 3 приведен пример индивидуального элемента OWL.
Листинг 3. Индивидуальный элемент OWL <owl:Thing rdf:about="SmithAccount"> <rdfs:type="#Account"/> </owl:Class>
Элемент rdf: type это свойство RDF, которое связывает индивидуальный элемент с тем классом, к которому он принадлежит. Листинг 3 указывает, что элемент Smith Account принадлежит к типу Account.
На рисунке 2 показаны основные блоки онтологии OWL.
IT-системы организуют значения с помощью реляционных моделей данных, линейных файлов, объектно ориентированных моделей или специально разработанных моделей данных. Время от времени, в связи с изменениями бизнес требований, возникает необходимость добавления новых элементов и связей в реляционные модели данных или объектно ориентированные модели.
Более того, если организация использует множественные приложения от различных поставщиков, то придется копировать одни и те же модели во все базы данных приложений. Например, банк предлагает набор различных продуктов для обслуживания разнообразных категорий клиентов. Корпоративному клиенту может потребоваться услуга по обнаружению мошенничества, а обычному потребителю окажется достаточно функциональных возможностей интерактивного осуществления банковских операций с помощью интернета. Обычно банк приобретает приложения у нескольких поставщиков, но каждое из них повторяет одну и ту же общую информацию номера счетов, имена клиентов и т. д. в своей базе данных. По мере того, как организация добавляет новые продукты для удовлетворения растущих запросов бизнеса, одна и та же избыточная информация распространяется по всей корпорации.
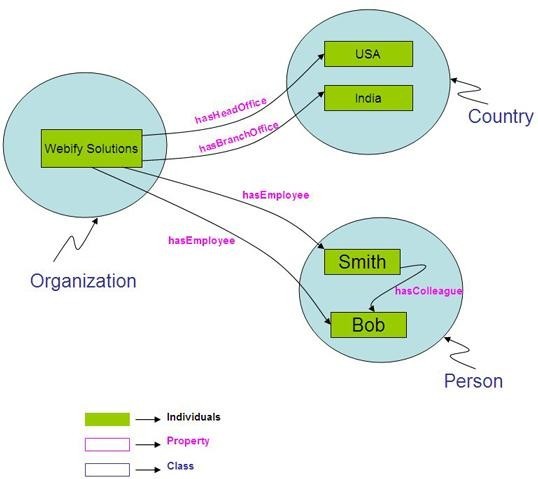
Рис. 2. Онтология OWL, описывающая организационную структуру компании Webify Solutions
Целый ряд услуг является общим для всех приложений, например, просмотр банковских транзакций и электронных переводов. Каждая из этих услуг также дублируется в формате, присущем тому или иному приложению, что ведет к необходимости осуществления точечной интеграции.
Если же банк принимает подход, основанный на онтологии, то он может собирать и представлять общую информацию о продуктах в нейтральной по отношению к языку форме и сохранять эту информацию в центральном репозитории. С помощью такой общей адаптированной онтологии организация может обеспечивать единое стандартизированное представление данных для всех приложений. Такое стандартизированное представление позволяет точно извлекать необходимую информацию и без проблем осуществлять корпоративную интеграцию, поскольку бизнес- процессы и различные источники данных могут быть связаны ("отображены") друг с другом с помощью общей метамодели. Таким образом, общая онтология исключает необходимость в точечной интеграции и упрощает интеграцию приложений, сокращая избыточность данных и обеспечивая одно и то же семантическое значение для всех приложений, что облегчает поддержание функционирования банка и его обновление.
Интернет это крупнейший из когдалибо существовавших информационных репозиториев, причем его содержание все время растет и представлено на самых разнообразных языках и практически во всех областях знаний. Но в конечном счете становится все труднее находить смысл во всем этом содержимом. Поисковые системы способны находить информацию, содержащую определенные слова, но эта информация не всегда оказывается именно той, что требуется. Какой-то элемент всегда оказывается упущенным. Поиск основан на содержании страниц, но не на семантическом значении этого содержания или информации о странице.
Как только будет создан семантический интернет, он даст возможность разметки всего содержания интернета, описания каждого элемента информации и обеспечения семантического значения этих элементов. Таким образом, поисковые системы становятся более эффективными, чем сейчас, а пользователи могут находить именно ту информацию, которая им необходима. Организации, оказывающие различные услуги, способны индексировать их с особым значением. А пользователи будут в состоянии оперативно находить эти услуги, используя программные средства на основе интернета, и использовать их для своей пользы или в сочетании с другими услугами.
Для того чтобы соответствующим образом моделировать и управлять СОА (сервис ориентированной архитектурой), корпоративные архитекторы должны поддерживать активное представление услуг, доступных для корпорации. В частности, для выявления и организации своих услуг, архитекторы должны использовать передовой опыт в моделировании и объединении услуг с использованием метаданных, преобразовывать бизнес-логику в метаданные для динамического объединения и осуществлять управление с помощью метаданных. Онтология обеспечивает очень мощный и гибкий способ для агрегирования, визуализации и нормализации этого слоя услуг с помощью метаданных.
Онтология это сеть концепций, связей и ограничений, которые обеспечивают контекст для данных и информации, а также для процессов. Онтология способствует улучшению обнаружения услуг, моделирования, объединения, посредничества и семантического взаимодействия сетей. Она усовершенствует для пользователей способы поиска, изучения и взаимодействия со сложными информационными пространствами метаданных. Бизнес-онтология это формальная спецификация бизнес концепций и их взаимосвязей, которая улучшает машинные причинно-следственные связи и взаимодействия.Бизнес-онтология связывает системы, используя метаданные, во многом аналогично тому, как база данных объединяет разрозненные данные. Такая абстракция обеспечивает гибкость и подвижность, поскольку позволяет легко менять интерфейсы, а также добавлять новые ресурсы и пользователей, причем даже во время работы системы.
Семантика это будущее сервис ориентированной интеграции. Семантические технологии обеспечивают существование определенного уровня абстракции над существующими IT технологиями. Этот уровень позволяет осуществлять связь данных, содержания и процессов между различными видами бизнеса и изолированными IT структурами. Наконец, с точки зрения взаимодействия людей, семантические технологии добавляют новый уровень семантических порталов, которые обеспечивают гораздо более аналитические, соответствующие теме и контексту взаимодействия, чем те, которые доступны с помощью традиционных точечных подходов к интеграции, использующихся в информационных порталах.
В данной статье были представлены основные стандарты, составляющие технологии семантических сетей, а также причины, побуждающие организации использовать эти технологии. С помощью данных технологий организации могут создавать единое унифицированное представление данных во всех приложениях, что позволяет точно находить необходимую информацию, упрощает корпоративную интеграцию и интеграцию СОА, сокращает избыточность данных и обеспечивает единство семантических значений во всех приложениях. Все это, в свою очередь, облегчает разработку, поддержку и обновление приложений в пределах корпорации.
ЛИТЕРАТУРА
- "Роль онтологии в автономных компьютерных системах " by L. Stojanovic, J. Schneider, A. Maedche, S. Libischer, R. Studer, Th. Lumpp, A. Abecker, G. Breiter, and J. Dinger (IBM Research Journal, 2004): Discover the benefits when you use ontologies to describe knowledge and construct related autonomic computing systems.
- "Введение в Jena" by Philip McCarthy (developer Works, June 2004): Use RDF models in your Java applications with the Jena Semantic Web Framework.
- “Основы XML и технологий RDF для управления знанием” by Uche Ogbyji (developer Works, March 2002)
- "Конструирование основ сервис ориентированной архитектуры с помощью технологии J2EE" by Naveen Balani (developer Works, January 2004): Find out more about SOA programming.
- Предметная классификация с помощью DITA и SKOS (developer Works, October 2005)